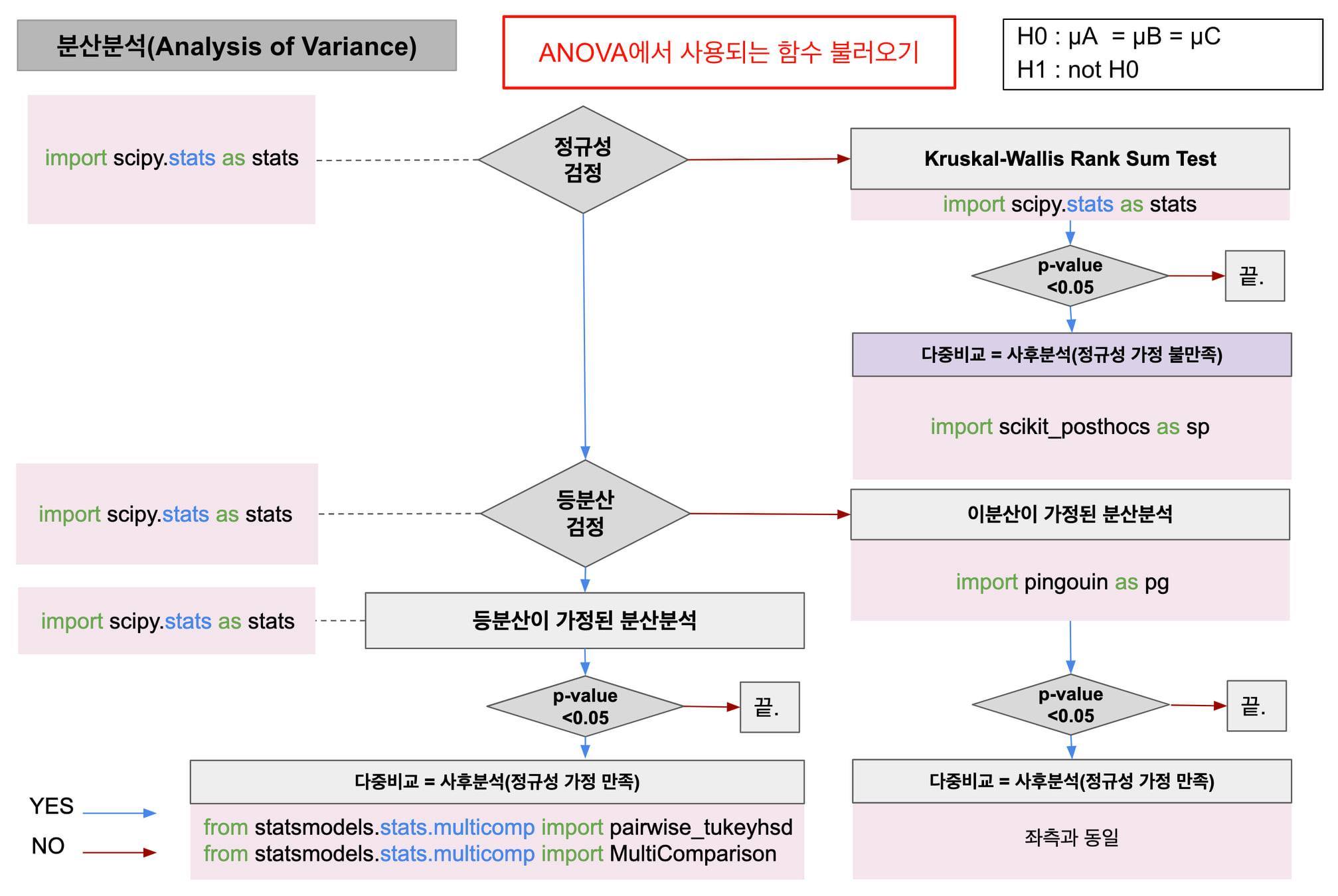
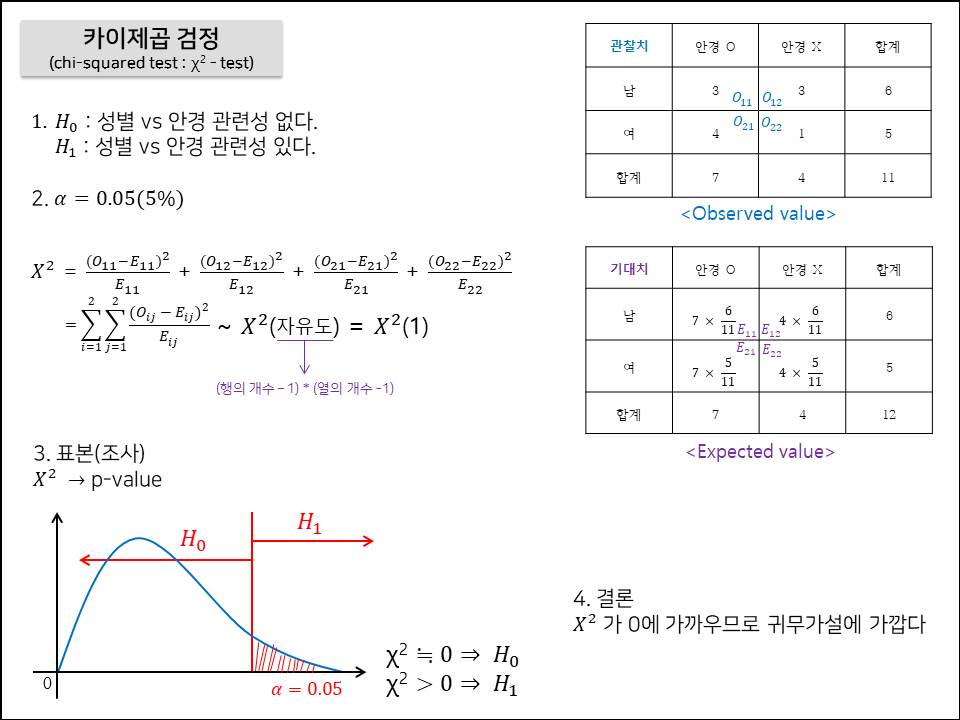
이전 게시물에 이어서 만약 등분산이었을 때의 분산분석을 해보자. stats.f_oneway(iris.loc[iris.species == "setosa", "petal_length"], iris.loc[iris.species == "versicolor", "petal_length"], iris.loc[iris.species == "virginica", "petal_length"]) ------------------------------------------------------------------------- F_onewayResult(statistic=1180.161182252981, pvalue=2.8567766109615584e-91) 등분산 일 때의 분산분석은 stats.f_oneway() 를 사..