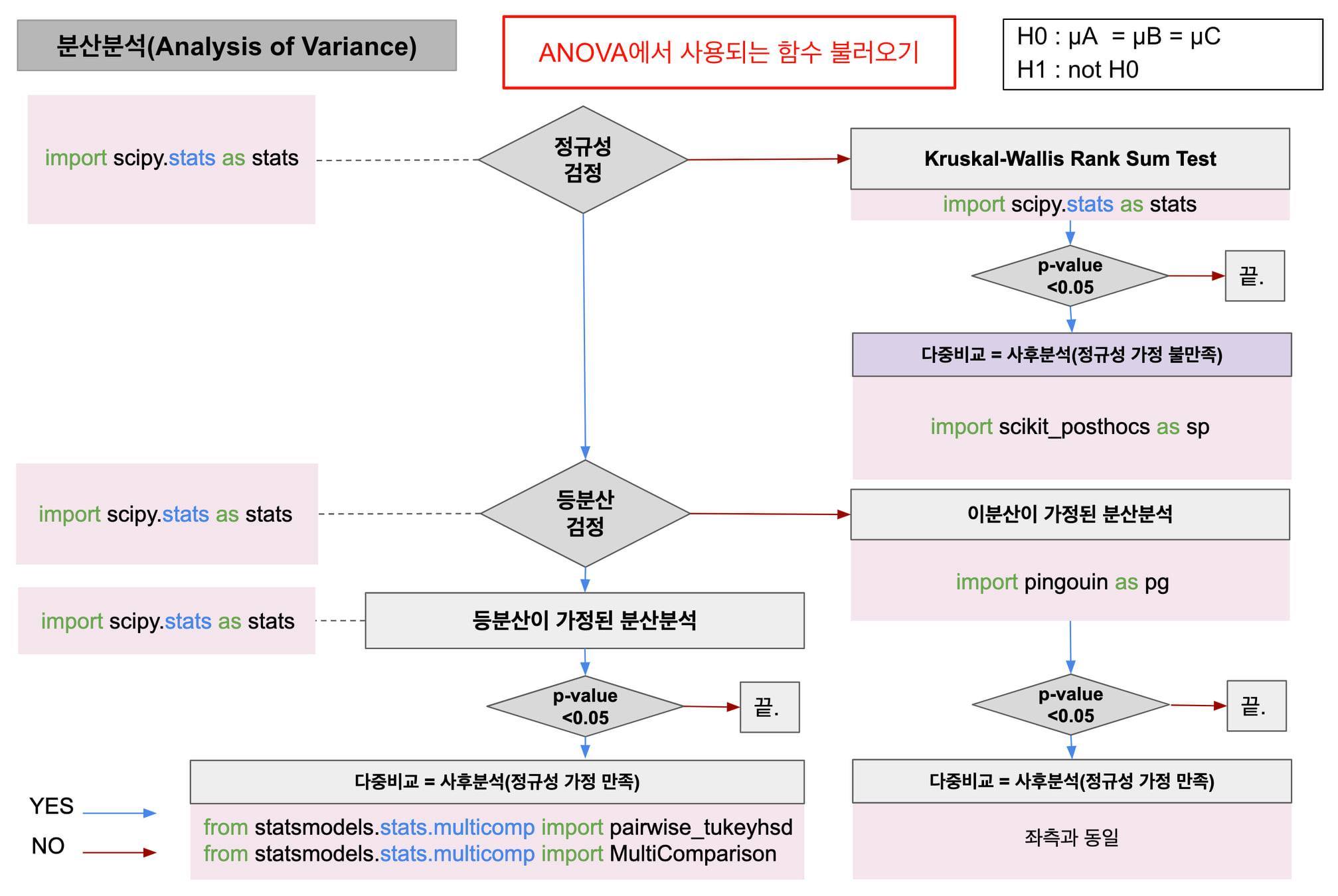
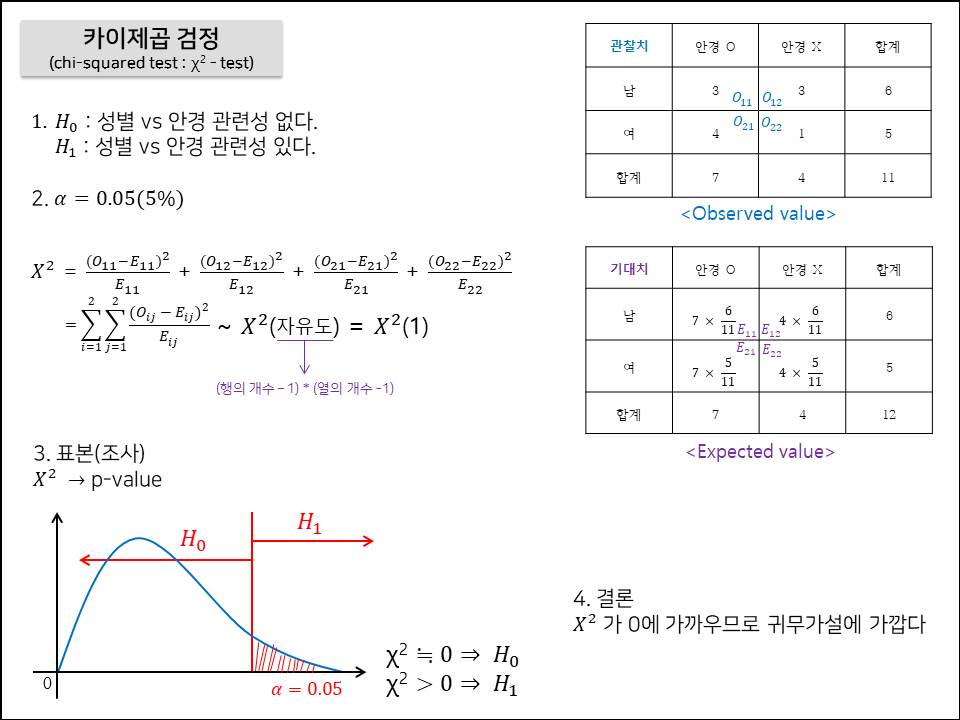
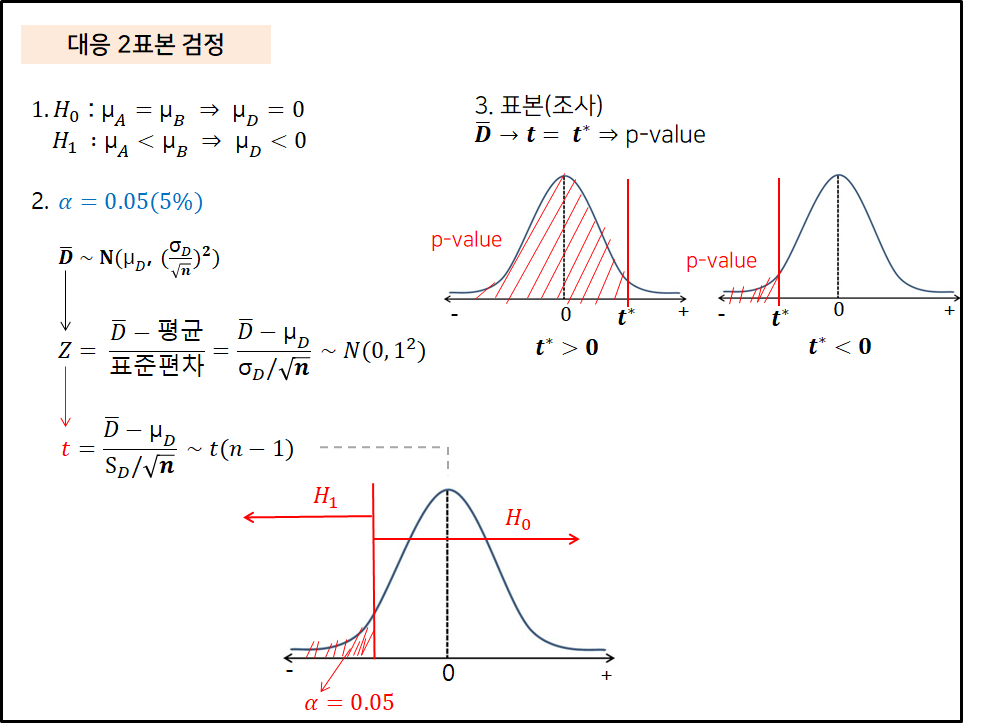
이전 게시물에 이어서 이번에는 상관 분석을 파이썬을 통해 알아보자. 귀무가설 : 꽃잎의 길이와 꽃받침의 길이 간에는 관련성(직선의 관계)이 없다.대립가설 : 꽃잎의 길이와 꽃받침의 길이 간에는 관련성(직선의 관계)이 있다. 1. Pearson stats.pearsonr(x = iris.petal_length, y = iris.sepal_length)---------------------------------------------------------------(0.8717537758865832, 1.0386674194497525e-47) Person 방법은 stats.pearsonr() 을 사용한다. 0.872 : 표본의 상관계수(r)0.000 : 유의확률 유의확률이 0.000 이므로 유의수준 0.05에..