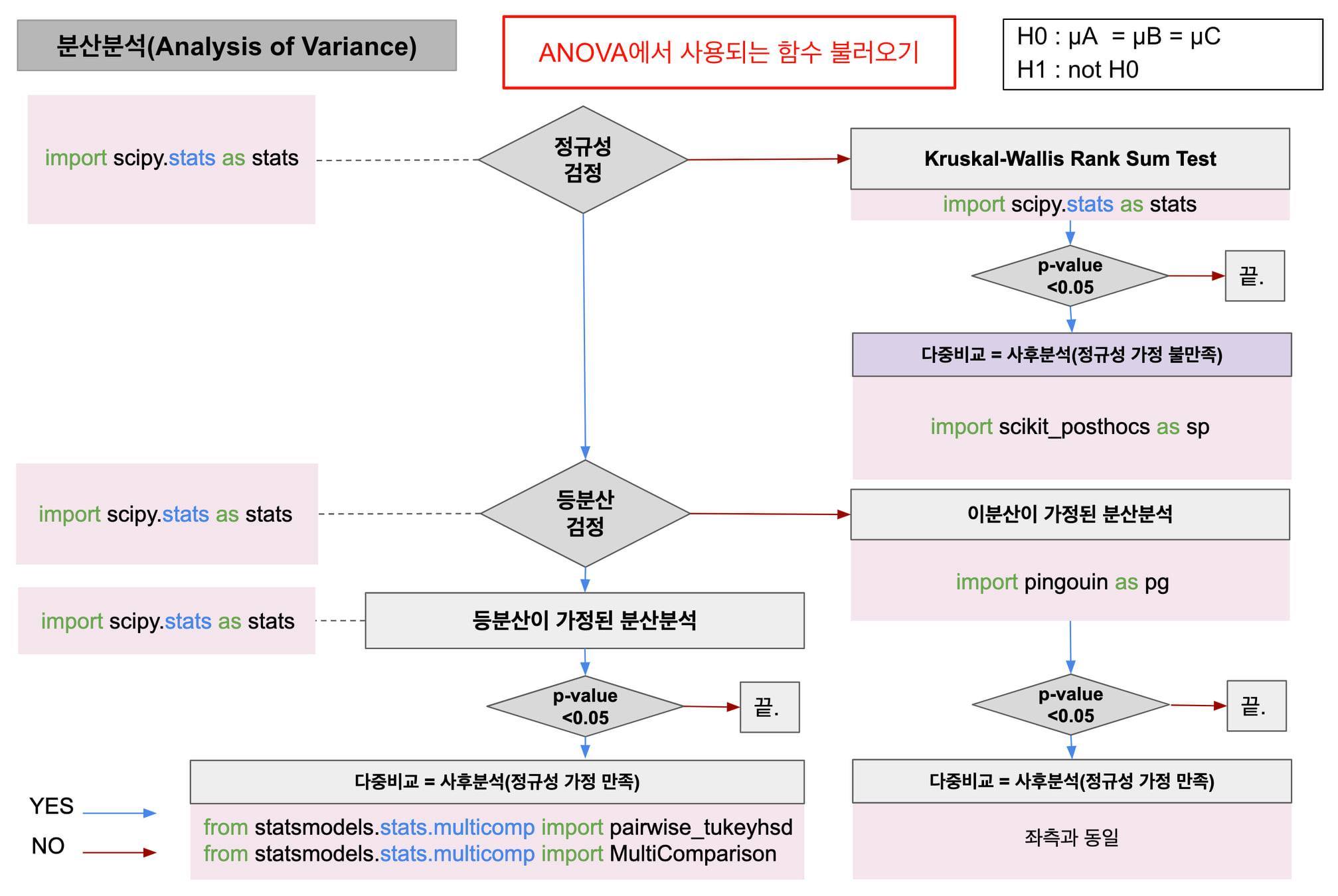
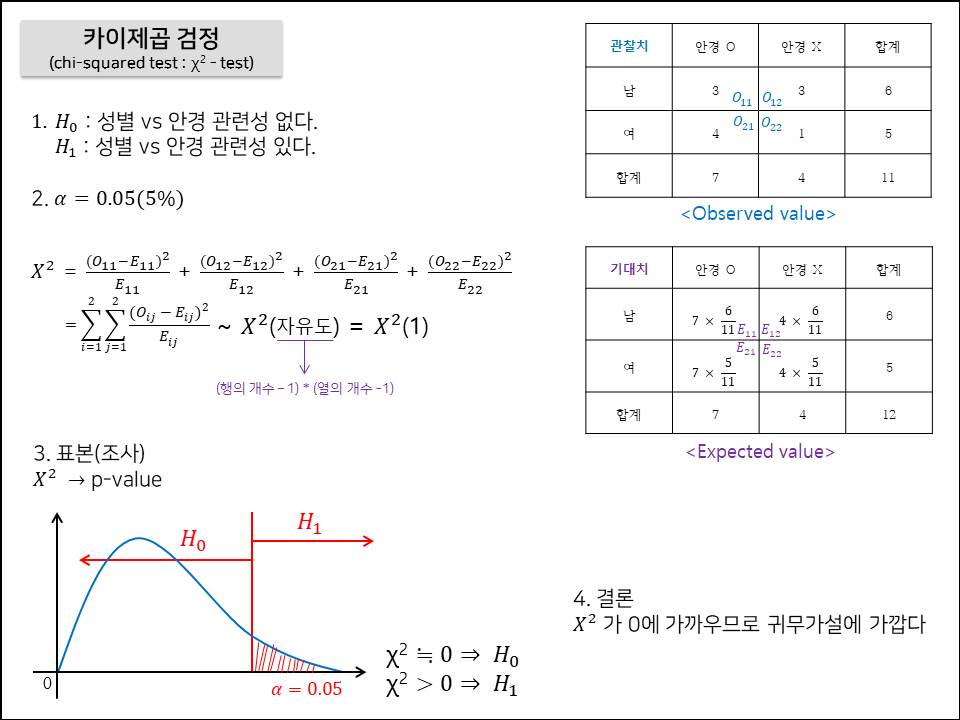
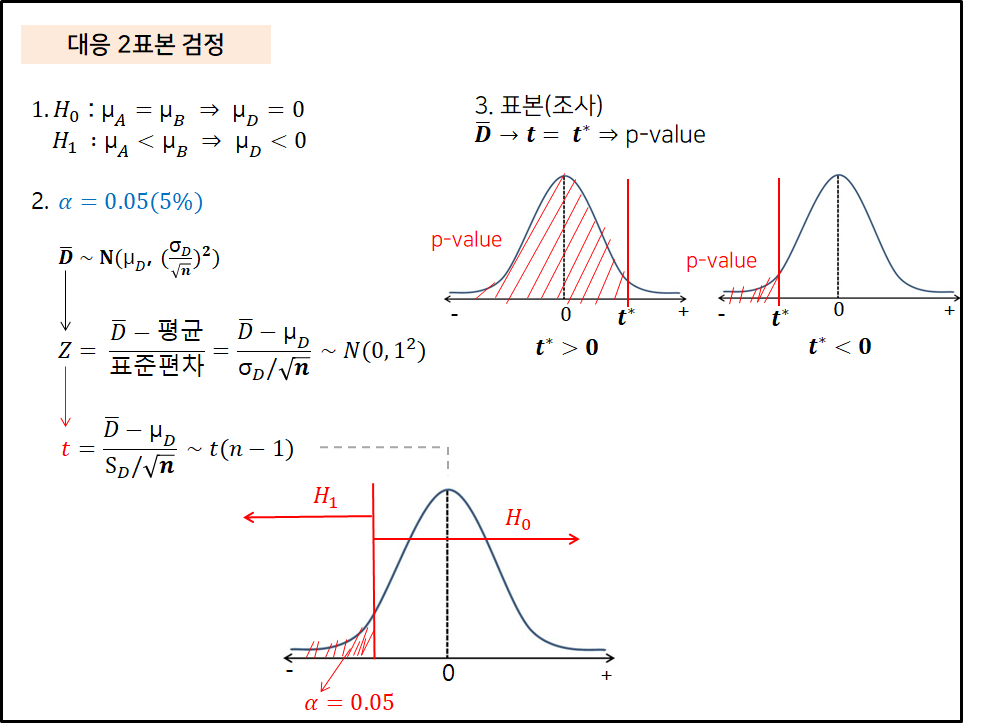
머신러닝을 시작하기 전에 알아야 할 것은 특성 공학(feature engineering) 이다. 특성 공학이란 머신러닝 프로젝트에서 훈련에 사용할 좋은 데이터(특성)들을 찾는 것이다. 에러, 이상치, 잡음으로 가득하면 결과가 좋지 않게 나오는 것은 당연하기 때문에 특성 공학에 시간을 쏟는 것은 절대 시간을 버리는 것이 아니다. 특성공학에는 두 가지 작업을 포함한다. 특성 선택(feature selection) : 가지고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택 특성 추출(feature extraction) : 특성을 결합하여 더 유용한 특성을 만든다. 모델이 새로운 샘플에 얼마나 잘 일반화될지 아는 유일한 방법은 새로운 샘플을 실제로 적용해보는 것이다. 그렇게 하기 위해 주로 쓰는 방법은 훈련 ..