이전 게시물에 이어서 만약 등분산이었을 때의 분산분석을 해보자.
stats.f_oneway(iris.loc[iris.species == "setosa", "petal_length"],
iris.loc[iris.species == "versicolor", "petal_length"],
iris.loc[iris.species == "virginica", "petal_length"])
-------------------------------------------------------------------------
F_onewayResult(statistic=1180.161182252981, pvalue=2.8567766109615584e-91)등분산 일 때의 분산분석은 stats.f_oneway() 를 사용한다.
유의확률이 0.000 이므로 유의수준 0.05 에서 품종에 따라 꽃잎의 길이에 통계적으로 유의한 차이가 있다.
# 분산분석(ANOVA)
import statsmodels.api as sm
from statsmodels.formula.api import olsiris_result = ols("petal_length ~ species", data = iris).fit()
sm.stats.anova_lm(iris_result, type = 2)
결과값을 자세히 보자.

이전게시물부터 지금까지 배운 모든 요소들을 볼 수 있다.
k-1 = 2.0
n-k = 147.0
SSB = 437.1028
SSE = 27.2226
MSB = 218.551400
MSE = 0.185188
F(MSB/MSE) = 1180.161182
요소에 관한 자세한 내용은 이전 게시물을 참조하면 된다.
[Python] 분산 분석(ANOVA) : feat.(SST,SSE,SSB) - (1)
분산 분석(ANOVA : Analysis of Variance) k 개의 집단을 비교하여 다름을 판단하는 것. (k : 3개 이상의 유한한 개수) 분산 분석의 대립가설은 많은 경우의 수를 가지고 있다. 그래서 최소한 2개의 집단은 �
junsik-hwang.tistory.com
# 크루스칼-왈리스 순위합 검정(Kruscal-Wallis Rank Sum Test)
- k 집단 중 하나라도 정규성 가정이 깨질 때 사용하는 검정방식

데이터는 임의로 간단하게 만들었다.
귀무가설 : "태어난 달의 초반 중반 후반에 따라서 생활비 지출과 관련이 없다."
대립가설 : "태어난 달의 초반 중반 후반에 따라서 생활비 지출과 관련이 있다."
평균 순위합을 구한 것은 데이터가 많으면 순위합이 크기 때문이다.
만약에 귀무가설(용돈에 차이가 없다)이 맞다고 한다면 예상할 수 있는 기대값이 있을 것이다. (6, 6, 6)
다시 이야기하면, 평균 순위합과 기대값이 차이가 나지 않는다면 귀무가설, 차이가 많이 날수록 대립가설에 가깝다는 것.
행의 개수가 3개 이니 3-1로 자유도는 2이다. 결국 Chi-Square(2)를 따른다.

# 파이썬으로 보는 크루스칼-왈리스 순위합 검정(Kruskal-Wallis rank sum test)
stats.kruskal(iris.loc[iris.species == "setosa", "petal_length"],
iris.loc[iris.species == "versicolor", "petal_length"],
iris.loc[iris.species == "virginica", "petal_length"])
---------------------------------------------------------------------
KruskalResult(statistic=130.41104857977163, pvalue=4.803973591157605e-29)크루스칼-왈리스 순위합 검정은 stats.kruskal()을 사용한다.
Chi-square 값(검정 통계량) = 130.411
p-value = 0.000
유의확률이 0.000 이므로 유의수준 0.05 에서 품종에 따라 꽃잎의 길이에 통계적으로 유의한 차이가 나타났다.
# 단계별로 보는 분산분석
1단계. 정규성 검정
- 귀무가설 : 정규분포를 따른다.
- 대립가설 : 정규분포를 따르지 않는다.
setosa_normality = stats.shapiro(iris.loc[iris.species == "setosa", "petal_length"])
versicolor_normality = stats.shapiro(iris.loc[iris.species == "versicolor", "petal_length"])
virginica_normality = stats.shapiro(iris.loc[iris.species == "virginica", "petal_length"])
print("Setosa : ", setosa_normality)
print("Versicolor : ", versicolor_normality)
print("Virginica : ", virginica_normality)
--------------------------------------------------------------------------------
Setosa : ShapiroResult(statistic=0.9549766182899475, pvalue=0.05481043830513954)
Versicolor : ShapiroResult(statistic=0.9660047888755798, pvalue=0.1584833413362503)
Virginica : ShapiroResult(statistic=0.9621862769126892, pvalue=0.10977369546890259)Setosa : 유의확률 0.055 > 0.05 = 정규성 가정 만족
Versicolor : 유의확률 0.158 > 0.05 = 정규성 가정 만족
Virginica : 유의확률 0.110 > 0.05 = 정규성 가정 만족
모두 정규성 가정을 만족함.
2단계. 등분산 검정
- 귀무가설 : 등분산이다.
- 대립가설 : 이분산이다.
stats.levene(iris.loc[iris.species == "setosa", "petal_length"],
iris.loc[iris.species == "versicolor", "petal_length"],
iris.loc[iris.species == "virginica", "petal_length"])
---------------------------------------------------------------------
LeveneResult(statistic=19.480338801923573, pvalue=3.1287566394085344e-08)유의확률이 0.000 이므로 유의수준 0.05에서 이분산이다.
3단계. (이분산이 가정된) 분산분석
pg.welch_anova(dv = "petal_length", between = "species", data = iris)
유의확률이 0.005 이므로 유의수준 0.05에서 품종에 따라 꽃잎의 길이에 통계적으로 유의한 차이가 나타났다.
잠깐 다른 이야기.
- 모수적 방법(Parametric Method)
- 모집단의 분포를 가정할 수 있을 때 사용하는 방법
- ex) One sample t-test / Two sample t-test / Paired t-test / ANOVA
- 비모수적 방법(Non-Parametric Method)
- 모집단의 분포를 가정할 수 없거나 아주 약하게 가정할 때 사용하는 방법
- ex) Wilcoxon's signed rank test / Wilcoxon's rank sum test / Kruskal-Wallis rank sum test
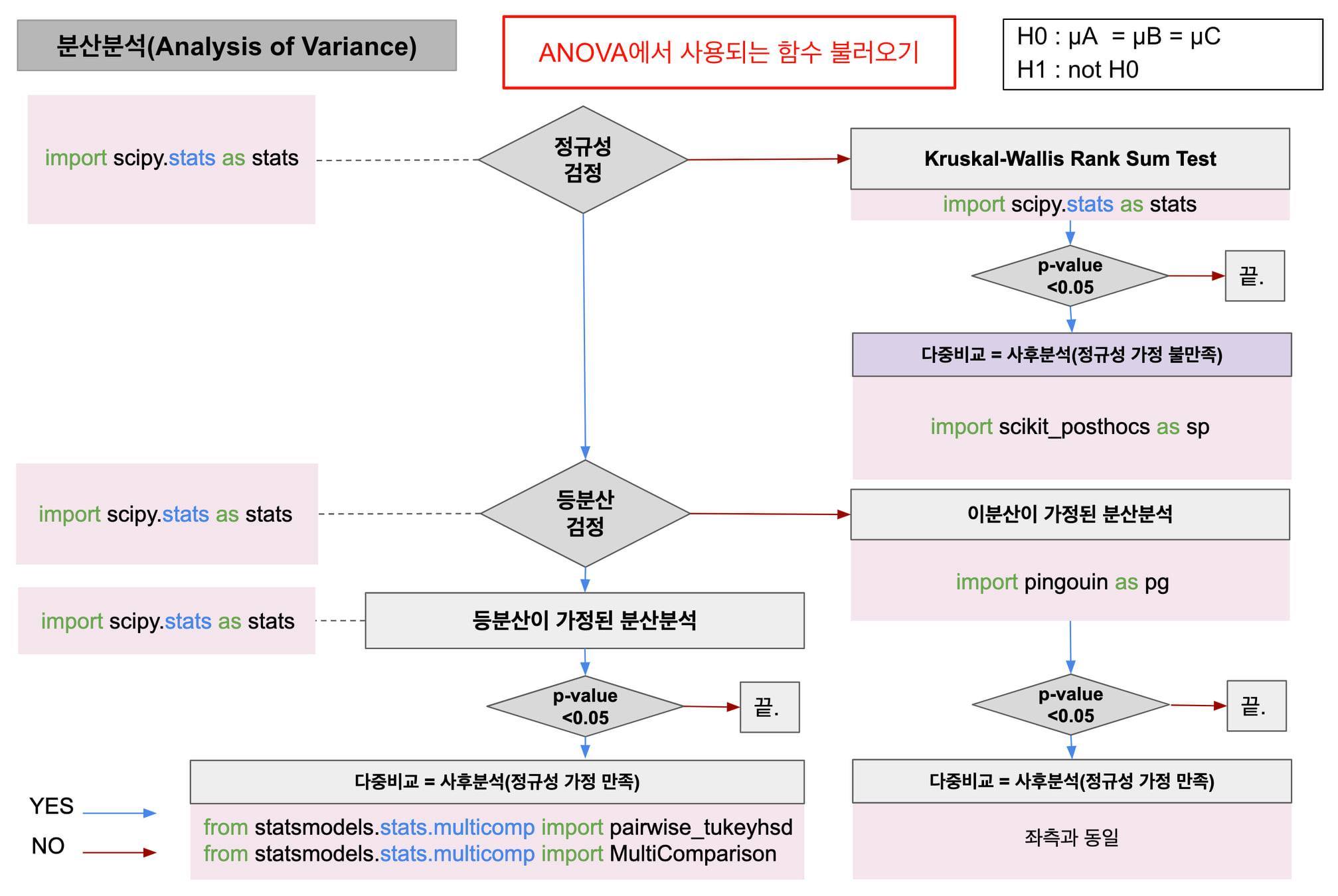
* 실습출처 : 2020 SBA아카데미 AI 데이터분석 개발자과정 : 기초 통계 (이부일 CEO님)
* 분산분석 알고리즘 사진 출처 : SBA아카데미 : 박지영(Jiyoung Park)
'데이터 분석 > 통계(Statistics)' 카테고리의 다른 글
| [Python] 상관 분석(산점도, 상관계수) with Python (0) | 2020.09.23 |
|---|---|
| [Python] 상관 분석(산점도, 상관계수) - Pearson, Spearman, Kendall (0) | 2020.09.19 |
| [Python] 분산 분석(ANOVA) : feat.(SST,SSE,SSB) - (1) (0) | 2020.09.09 |
| [Python] 카이제곱 검정(교차분석) (1) | 2020.09.03 |
| [Python] 대응 2표본 검정(Paired test) - (2) (0) | 2020.08.29 |